
Alexis M.,
Too Long; Didn't Read
IT projects do not fail by chance. They fail for avoidable reasons. The top 3: unclear requirements, lack of executive support, unrealistic schedules. The successful 30% aren’t smarter – they have better processes. You can have that too.

The scene nobody wants
You have just approved 2 million for a new system. The project was supposed to go live in 18 months. Best people, clear plan, everyone motivated.
14 months later: 800,000 over budget. Six months behind schedule. The CEO asks why nobody saw it earlier.
This is not your fault. It's the norm.
The Standish Group has been analyzing IT projects for 30 years. The results? Remarkably consistent - and remarkably depressing. 70% fail or miss their targets by a wide margin.
These are not isolated cases. This is a systemic problem.
(The good news: It can be fixed.)
Why projects die
After hundreds of projects we have supported, we keep seeing the same patterns.
Chaotic requirements
The project starts. The business owner knows the problem, but can't describe it precisely. IT tries to read minds.
Six weeks later, both sides understand completely different things.
Then comes scope creep: "Wait, we also needed that." "Oh yes, that too." In the end, you build something else - bigger, more complex, more expensive.
Unclear requirements cause 40% of project delays. The largest single cause.
Lack of executive support
The project needs decisions. Fast. The sponsor is busy. In five other projects. Nobody gives the go-ahead for critical decisions.
The project slows to 30% of its normal pace.
For projects with an active sponsor: 70% success rate. Without one: 30%.
Unrealistic timelines
"We need this in 6 months for the major client."
The project is actually a 12-month project. But the pressure is enormous. The estimate gets "adjusted." Everyone knows it's unrealistic. Nobody says it out loud.
Six months later: 60% complete. Panic mode. Overtime. Bugs that haven't been tested.
Projects with "accelerated timelines" have a 3x higher error rate.
The wrong team
You have Java developers. The project is a cloud migration to AWS with Kubernetes. Nobody has ever done that.
Or: you have developers, but no product owner who has time for questions. The designer is responsible for five projects.
Insufficient skills cost 1-3 weeks per quarter in rework.
Communication that doesn't work
The team is not co-located. Business and IT speak different languages. The status report arrives on Fridays - but nobody really knows what "yellow" means.
A major problem is noticed. The information goes to the tech lead. Then to the project manager. Then to the sponsor. Six days later, an emergency call is scheduled.
Communication problems cause 30% of delays.
For a deeper look, see our article How to make IT decisions that don't end in disaster.
What the successful 30% do differently
The projects that work are not led by smarter people. They have better systems.
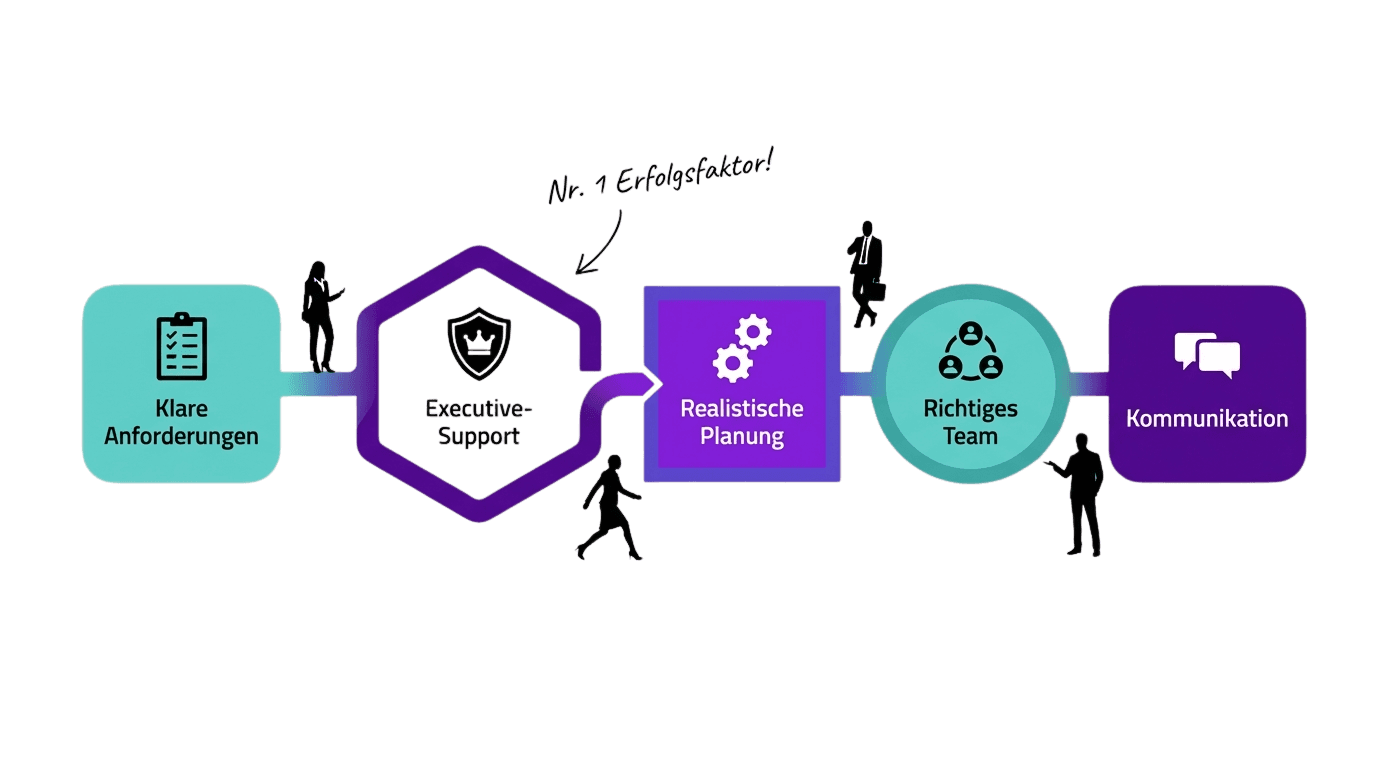
Clarify requirements before starting
8-10% of the budget in the requirements phase. That's not waste - that's insurance.
Workshops with all stakeholders. Documentation in one system, not in emails. Define a scope freeze point. After that: change requests with explicit costs.
Have a real sponsor
Not someone who starts the project and then disappears. Someone who invests time every month. Who removes blockers. Who makes decisions.
This is not optional. This is a requirement.
Plan realistically
Three-point estimates: optimistic, likely, pessimistic. 30-40% contingency for complex projects.
Say "no" to unrealistic deadlines. Or negotiate the scope. "6 months? Sure - but then an MVP with phase 2."
Assemble the right team
Not cobbled together. For an AWS project: an AWS-certified architect. At least one experienced cloud engineer.
A product owner with at least 30% of their time allocated. Not 5%.
Communicate daily
15-minute standups. What are you doing today? What are you stuck on?
Weekly syncs between business and tech. What have we achieved? Where are the surprises?
Clear escalation paths. If a blocker lasts longer than two days, it gets escalated.
The most common mistake
The biggest mistake we see: hoping it will work out.
No risk register. No contingency. No plan B scenarios.
"What if the database doesn't perform?" - No planning.
"What if the vendor disappears?" - No backup solution.
"What if the senior developer leaves?" - No plan.
Projects without risk management have 45% more "surprises."
Successful projects list their risks. Assess them. Have a plan for when they occur. Review them monthly.
That's not paranoid. That's professional.
When things are already going wrong
Sometimes you notice too late. Month 8 of 18. 30% over budget. Requirements chaotic.
Is it over? Not necessarily.
Be honest. Sit down with the sponsor. "The project is in trouble." Be clear: budget, timeline, or scope?
Scope triage. What do you really need? What is nice to have? What can be phase 2? Cutting 20-30% of the nice-to-haves can save the project.
Replan. Not with the original unrealistic estimates. Instead: where are we now? From here, how much longer do we need?
The new baseline may be 24 months instead of 18. That's okay. Better to plan ahead than panic at the end.
Conclusion
70% of IT projects fail. That's a fact.
But they do not fail because people are stupid. They fail because processes are missing. Because communication is broken. Because requirements are chaotic. Because risks are ignored.
These are all things you can control.
The successful 30% are not smarter. They have better systems. Better communication. Clear requirements. Risk awareness. Real executive support.
You can have that too. It doesn't take much - but it does take discipline.
And honesty. The willingness to say: "This will not work unless we do X."
If you're ready for that, you belong to the 30%.


